|
Record based access to streams is a powerful feature that allows
DB-like manner to be used when working with files or other streams. Even
without the true DB features like indexing, SQL and so on - record based
access is well known and used widely by the C++, Pascal and VB
programmers. However the script languages do not provide such tools and
even the compiled languages often need a bit more functionality and COM
compatibility.
The classes involved are SFField, SFRecord
and SFFilter. In general the flat files are
well-known and there is nothing unusual in this set of objects -
SFRecord uses SFField objects to describe the structure of a single
record. Then SFRecord is bound to a stream through a SFFilter object and
allows the application to navigate through the stream as set of records.
The navigation includes random access, MovePrev/MoveNext and other
capabilities. Probably the only specific is the SFFilter object. In most
cases the programming tools which support random accessed files leave
the encoding problems to the application, but here the SFFilter object
is supposed to do the job - e.g. UNICODE to ANSI conversion or byte
ordering. Custom filters can be implemented by other developers and used
with binary streams which require some other features or encoding. The
library contains only one default SFFilter that is enough for the
Windows applications, but if certain application needs to process data
generated on other OSes it may need to implement custom filter if the
data requires specific conversion.
Also the SFFilter object can be used directly to gain direct access
to the binary stream and read/write single values from/to it. This can
be very useful if the application deals with complex file formats and
needs to read some headers and other parts with non-record based nature.
The type of the value read/written is specified by the application so
every supported data type can be read/written from/to any position of a
stream. Still the application can benefit of the built-in encoding
capabilities of the filter and after specifying the settings it will not
need to care about the string conversion from/to UNICODE/ANSI for
example. However the direct usage requires deep knowledge about the file
format processed and the data types and their sizes in COM. One little
example are the MP3 files. You need to know how to read 32 bits - e.g.
which type used in the script languages is 32 bits long (VT_I4 - vbLong
in VBScript).
How this works?
Record based access to streams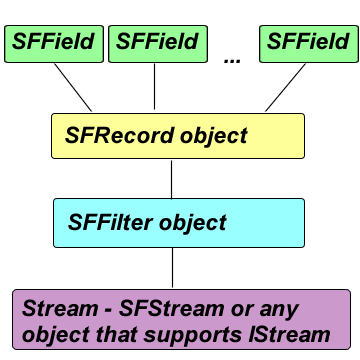
The full structure involved in the record based access to streams
includes (as shown on the picture): one SFRecord object, many SFField
objects, one SFFilter object and a stream object. The application deals
directly with the SFRecord object and its fields (the SFField objects
attached to the record) and usually does not need to access the other
objects in the chain.
The SFRecord object has navigation members (such as Move, MoveNext,
MovePrev etc.). The application is responsible to construct the chain
and after that point the operations are done by navigating through the
records and using the ReRead and Update methods if needed. In other
words the process is very DB-like. But what happens inside?
SFRecord together with the SFFields configured is a a definition of
an abstract record that contains the data defined by the fields in the
same order as the fields appear in the record itself. For example there
could be an integer field, then a text field with length 20 characters,
then a Boolean field and so on. However this information is not enough
to define how the data will be written/read to/from the stream itself.
The string can be saved as UNICODE but also it can be saved in ANSI
character set. The numbers can be in Intel byte order (less significant
bytes first) or they can be stored with Motorola byte order (most
significant bytes first). In general such kind of coding problems are
global for the stream - e.g. in almost any possible case all the strings
are encoded the same way and the numbers are ordered in same manner
throughout the entire stream (in all the records). Therefore it is
efficient to configure such kind of parameters somewhere in the middle
between the record definition which is formal and the real stream which
is most likely a physical storage. And the SFFilter object is the object
responsible to do this.
The SFFilter's role does not end with pre-coding of the data but also
includes some advanced features - like buffering. So the SFFilter object
incorporates capabilities allowing the SFRecord or the application
directly (see the next section) to read/write values of specified
type/size from/to the stream without need to care about their
representation. Of course the filter must be configured before using it
but after that point the physical representation is no longer of concern
for the using application. To simplify the development process
SFRecord and the SFFilter are tightly integrated internally and the
default behavior of the SFRecord object includes implicit creation and
configuration of a SFFilter object when binding to a stream. The
application can access the implicitly created filter through the
SFRecord.Filter property and change some settings. This limits the
initialization process to the record definition only (defining the
fields) and optionally a line or two to set specific settings to the
filter when needed. We decided to implement this default behavior as
the most efforts saving one, but the flexibility is not forgotten. A
custom filter can be passed to the SFRecord in binding operations and
also the filter can be accessed directly when the application needs to
bypass the SFRecord defined abstract structure. The developer may
choose how deep he needs to go and there is no need to understand all
the details at once in order to use the objects.
A simple illustration of a typical process:
We suppose the naxp1vbs.asp file has been included (for named
constants).
The application opens the stream
Set sf = Server.CreateObject("newObjects.utilctls.SFMain")
Set strm = sf.OpenFile("C:\Myrecords.bin",cSFR)
Now we need to create SFRecord
Set rec = Server.CreateObject("newObjects.utilctls.SFRecord")
And configure it - add the fields. We suppose we know the record
structure. The structure of the record can be known for the
application by design or can be extracted from a saved description -
for example configuration file.
rec.AddField "Field1", vbString, 20
rec.AddField "Field2", vbLong
Bind the record to the stream using the default filter (implicitly
created)
rec.BindTo strm
Perform filter configuration if needed. Suppose we know the texts
in the file are ANSI, but UNICODE is default for the filter so we need
to change this.
rec.Filter.unicodeText = False
As we changed the filter configuration we need to give it chance to
recalculate the record physical representation and we need to ReBind
the record.
rec.ReBind
Now we are ready to use the record. Lets read 5 records beginning
from the 5-th record.
If Not rec.Move(5, cStreamBegin) Then
' Error handling code
End If
For I = 1 To 5
Response.Write rec("Field1") & " " & rec("Field2")
If Not rec.MoveNext Then
' Exit cycle/sub/function
End If
Next
The Move methods return True if the record has been read and False
otherwise. So we can determine end of the file by using the return
value, but we can do it in more DB-like manner - lets read the entire
file and print the records with Field2 >10:
rec.MoveFirst
While Not strm.EOS
If rec("Field2").Value > 10 Then
Response.Write "Field1 = " & rec("Field1") & ", Field2=" & rec("Field2").Value
End If
rec.MoveNext
Wend
And finish our work. This can be omitted if the script ends here
and the objects will not be reused.
rec.UnBind
strm.Close
Similar is the process if we are going to write or read/write the
stream. Note that we check the EOS property over the stream object
and not over the record. The SFRecord object uses the stream
position kept by the stream - this allows the SFRecord to operate
without too much dependencies on stream features. For example using
the Read/Write methods of SFRecord instead of navigational methods (MoveXXXX)
it can be used to read or write sequentially records from non-seekable
stream. Another benefit is ability to change the stream position and
re-read the record from the new position and then navigate from it.
In other words the simple usage makes the stream (file or anything
else) to look like a DB table, but we are also able to break this
rule and position the record on random position in the stream and
continue. |